


Weekend Reading,15 de junio
Weekend Reading,15 de junio
Los 10 papers mas populares de la semana


Bienvenido a The Background, en esta ocasión te presento una recopilación de los 10 artículos mas populares sobre inteligencia artificial de esta semana, espero esta lectura te sea de ayuda para ampliar tus conocimientos y habilidades:
Mixture-of-Agents Enhances Large Language Model Capabilities

Este artículo presenta un enfoque novedoso para aprovechar las fortalezas colectivas de múltiples grandes modelos de lenguaje (LLM) mediante una metodología de Mezcla de Agentes (MoA). Cada capa en la arquitectura MoA está compuesta por múltiples agentes LLM que utilizan las salidas de las capas anteriores para generar respuestas. Este enfoque logra un rendimiento de vanguardia en benchmarks como AlpacaEval 2.0, MT-Bench y FLASK, superando a GPT-4 Omni.
The Background Note: Este método podría mejorar significativamente el rendimiento y las capacidades de los LLM, proporcionando un marco robusto para integrar múltiples modelos y abordar tareas complejas de manera más efectiva.
CRAG -- Comprehensive RAG Benchmark

El Benchmark Integral de RAG (CRAG) tiene como objetivo evaluar los modelos de generación aumentada por recuperación (RAG) utilizando un conjunto diverso de pares de preguntas y respuestas en varios dominios. CRAG incluye 4,409 pares y simula búsquedas web y en gráficos de conocimiento, destacando las limitaciones actuales de los modelos RAG y sugiriendo direcciones para futuras investigaciones.
The Background Note: CRAG sirve como una herramienta crucial para mejorar los sistemas de preguntas y respuestas, enfatizando la necesidad de manejar mejor información diversa, dinámica y compleja.
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation

LlamaGen introduce una nueva familia de modelos de generación de imágenes basados en enfoques autoregresivos, tradicionalmente utilizados en modelos de lenguaje. Estos modelos superan a los populares modelos de difusión al reevaluar la tokenización de imágenes, la escalabilidad y la calidad de los datos de entrenamiento, logrando resultados notables en la generación de imágenes de alta resolución.
The Background Note: El enfoque de LlamaGen podría transformar las tecnologías de generación de imágenes, proporcionando alternativas escalables y eficientes para la creación de contenido visual digital y de medios.
Husky: A Unified, Open-Source Language Agent for Multi-Step Reasoning
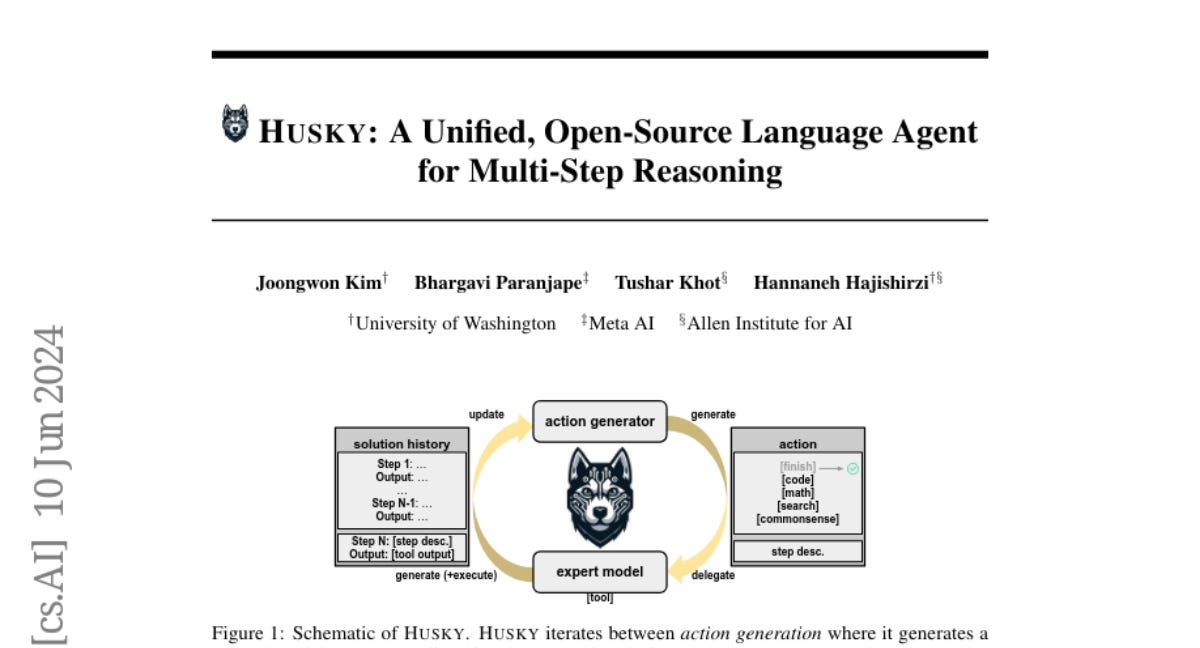
Husky es un agente de lenguaje de código abierto diseñado para realizar tareas complejas que involucran razonamiento numérico, tabular y basado en conocimiento. Itera entre generar acciones y ejecutarlas utilizando modelos expertos, superando a los agentes de lenguaje anteriores en varios benchmarks. HuskyQA evalúa el razonamiento mixto de herramientas, destacando el rendimiento superior de Husky.
The Background Note: Husky representa un avance significativo en el desarrollo de agentes de lenguaje versátiles capaces de manejar tareas complejas de razonamiento, cruciales para aplicaciones avanzadas de IA.
An Image is Worth 32 Tokens for Reconstruction and Generation

Este artículo presenta TiTok, un Tokenizador Unidimensional que transforma imágenes en secuencias latentes compactas, reduciendo las demandas computacionales y mejorando la eficiencia de generación. TiTok supera significativamente a los métodos convencionales de tokenización 2D en benchmarks de generación de imágenes de alta resolución.
The Background Note: El método innovador de TiTok en la tokenización de imágenes podría mejorar drásticamente la eficiencia y efectividad de los modelos generativos, impactando aplicaciones en arte AI y realidad virtual.
McEval: Massively Multilingual Code Evaluation

McEval es un benchmark multilingüe de código que abarca 40 lenguajes de programación con 16,000 muestras de prueba, diseñado para evaluar los LLM de código en contextos multilingües. McEval incluye tareas desafiantes para la comprensión, completado y generación de código, destacando la necesidad de conjuntos de datos multilingües más diversos y robustos.
The Background Note: McEval empuja los límites de los LLM de código, fomentando el desarrollo de herramientas más versátiles y potentes para las necesidades globales de programación.
NaRCan: Natural Refined Canonical Image with Integration of Diffusion Prior for Video Editing

NaRCan integra un campo de deformación híbrido y un prior de difusión para generar imágenes canónicas naturales de alta calidad a partir de videos de entrada. Este enfoque mejora el manejo de dinámicas de video complejas y acelera el entrenamiento, superando los métodos actuales de edición de video.
The Background Note: NaRCan ofrece una herramienta poderosa para la edición de video, permitiendo la creación de contenido más eficiente y de alta calidad, esencial para las industrias de medios y entretenimiento.
MotionClone: Training-Free Motion Cloning for Controllable Video Generation

MotionClone permite la generación de videos controlables basados en movimientos sin la necesidad de entrenar modelos. Utiliza atención temporal y guía semántica consciente de la ubicación para clonar los movimientos de videos de referencia. Este enfoque demuestra superioridad en fidelidad de movimiento, alineación textual y consistencia temporal, comparado con métodos previos.
The Background Note: MotionClone podría revolucionar la generación de videos al proporcionar un método flexible y eficiente para crear contenido dinámico y contextualmente rico, beneficiando industrias como el entretenimiento y la publicidad.
Depth Anything V2

Depth Anything V2 se centra en la estimación monocular de profundidad, ofreciendo predicciones más finas y robustas. El modelo utiliza imágenes sintéticas y aumenta la capacidad del modelo maestro, superando en eficiencia y precisión a los modelos basados en Stable Diffusion. Ofrecen modelos de diferentes escalas, desde 25M hasta 1.3B parámetros, para soportar diversos escenarios.
The Background Note: Este modelo podría mejorar aplicaciones en conducción autónoma, robótica y realidad aumentada al proporcionar capacidades de percepción de profundidad más precisas y eficientes.
An Image is Worth More Than 16x16 Patches: Exploring Transformers on Individual Pixels

Este estudio muestra que los transformadores estándar pueden procesar imágenes de manera efectiva al tratar cada píxel como un token, cuestionando el uso convencional de parches de 16x16. Este enfoque logra un rendimiento competitivo en tareas de clasificación de objetos, aprendizaje auto-supervisado y generación de imágenes.
The Background Note: Este hallazgo podría abrir nuevas direcciones en visión por computadora, alentando el desarrollo de arquitecturas neuronales más flexibles y potentes.
Gracias por leer The Background, no olvides compartir este correo con quien creas que le servirá. Hasta la próxima 👋