


Weekend Reading, 13 de Julio
Weekend Reading, 13 de Julio
Los 10 papers de IA mas populares - 13/07/2024

Bienvenido a The Background, en esta ocasión te presento una recopilación de los 10 artículos mas populares sobre inteligencia artificial de esta semana, espero esta lectura te sea de ayuda para ampliar tus conocimientos y habilidades:

1. Unveiling Encoder-Free Vision-Language Models

Este artículo presenta un modelo de visión-lenguaje (VLM) sin codificador que elimina la necesidad de codificadores de visión. El modelo, llamado EVE, utiliza un decodificador unificado para las representaciones de visión y lenguaje, y mejora la capacidad de reconocimiento visual a través de una supervisión adicional. EVE puede rivalizar con VLMs basados en codificadores utilizando solo 35M de datos públicos.
The Background Note📝: Aunque EVE promete una mayor eficiencia, su dependencia de supervisión adicional podría limitar su aplicabilidad en contextos de datos no supervisados.
2. FunAudioLLM: Voice Understanding and Generation Foundation Models for Natural Interaction Between Humans and LLMs

FunAudioLLM introduce modelos para mejorar la interacción por voz entre humanos y grandes modelos de lenguaje (LLMs). SenseVoice maneja el reconocimiento de voz y CosyVoice facilita la generación de voz multilingüe. Estos modelos permiten aplicaciones como traducción de voz y narración de audiolibros expresiva.
The Background Note📝: La implementación de estos modelos podría revolucionar la interacción por voz, pero su adopción masiva dependerá de la accesibilidad y facilidad de integración en sistemas existentes.
3. AriGraph: Learning Knowledge Graph World Models with Episodic Memory for LLM Agents

AriGraph propone un método para que los agentes LLM acumulen y actualicen conocimientos utilizando un gráfico de memoria que integra memorias semánticas y episódicas. Este enfoque mejora la capacidad del agente para tareas complejas mediante una recuperación asociativa eficiente.
The Background Note📝: AriGraph ofrece una prometedora mejora en la planificación y toma de decisiones de los agentes LLM, pero su eficacia en entornos más diversos aún está por comprobarse.
4. MJ-Bench: Is Your Multimodal Reward Model Really a Good Judge for Text-to-Image Generation?

MJ-Bench es un benchmark diseñado para evaluar la capacidad de los jueces multimodales en la generación de imágenes a partir de texto. Evalúa la alineación, seguridad, calidad de imagen y sesgo de estos modelos, destacando que los modelos VLMs cerrados generalmente proporcionan mejor retroalimentación.
The Background Note📝: Aunque MJ-Bench es una herramienta valiosa para evaluar modelos, su dependencia de modelos cerrados puede limitar su utilidad en investigaciones abiertas.
5. LLaMAX: Scaling Linguistic Horizons of LLM by Enhancing Translation Capabilities Beyond 100 Languages
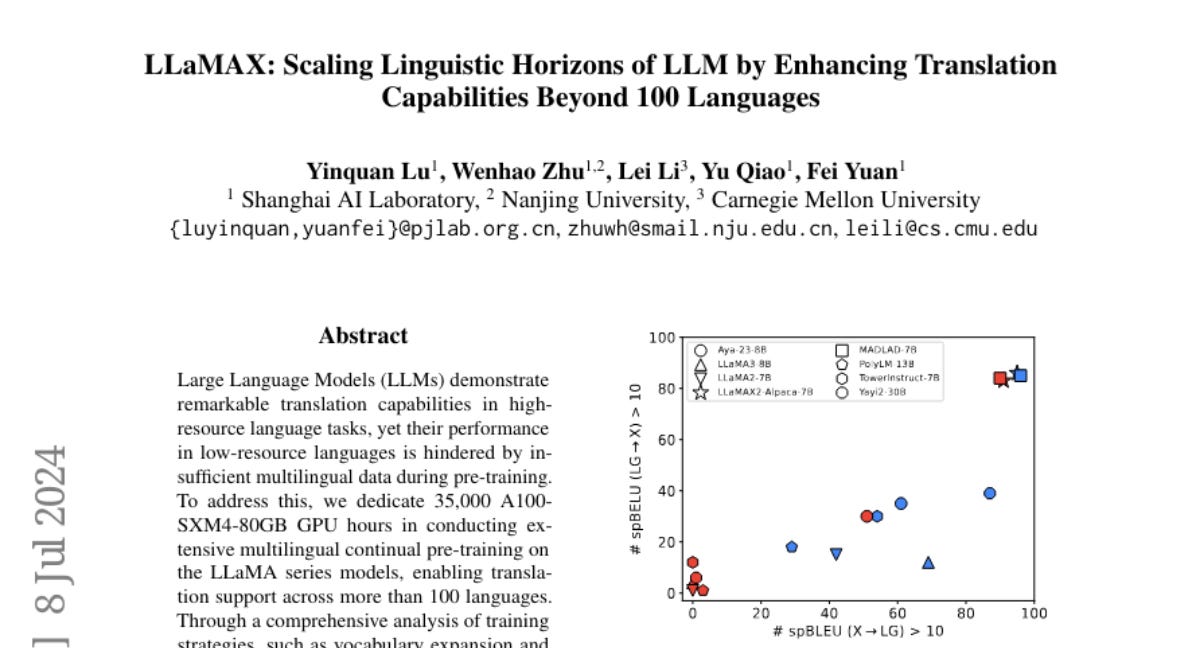
LLaMAX mejora las capacidades de traducción de los LLM a más de 100 idiomas a través de un preentrenamiento multilingüe extenso. Supera en rendimiento a otros LLMs de código abierto y está a la par con modelos de traducción especializados.
The Background Note📝: LLaMAX muestra un avance significativo en la traducción multilingüe, pero la eficiencia de su entrenamiento intensivo en GPU podría ser un obstáculo para su implementación generalizada.
6. Associative Recurrent Memory Transformer

ARMT es una arquitectura que combina la autoatención de transformadores con la recurrencia a nivel de segmento para procesar secuencias muy largas en tiempo constante. Establece un nuevo récord en la evaluación multi-tarea BABILong.
The Background Note📝: ARMT promete mejorar la eficiencia en el procesamiento de secuencias largas, pero su implementación en aplicaciones reales aún necesita validación práctica.
7. Vision language models are blind

Este artículo revela que los modelos de lenguaje con capacidades visuales, como GPT-4o y Gemini 1.5 Pro, fallan en tareas visuales simples que los humanos encuentran triviales. Esto cuestiona su eficacia en la comprensión visual detallada.
The Background Note📝: La incapacidad de estos modelos para realizar tareas visuales básicas destaca una importante limitación que debe abordarse para aplicaciones confiables.
8. AgentInstruct: Toward Generative Teaching with Agentic Flows

AgentInstruct es un marco para crear grandes cantidades de datos sintéticos de alta calidad para entrenar LLMs. Demuestra mejoras significativas en varios benchmarks al postentrenar modelos con datos generados automáticamente.
The Background Note📝: Aunque AgentInstruct muestra mejoras, la calidad de los datos sintéticos y su impacto en la generalización del modelo aún requieren más estudio.
9. Video-STaR: Self-Training Enables Video Instruction Tuning with Any Supervision

Video-STaR es un enfoque de autoentrenamiento para utilizar cualquier conjunto de datos de video etiquetados en la instrucción de videos para LLMs. Mejora la comprensión general de video y la adaptación a nuevas tareas con supervisión existente.
The Background Note📝: Video-STaR ofrece un enfoque novedoso para el entrenamiento de LLMs en video, pero su eficacia depende de la calidad y diversidad de los datos de video utilizados.
10. PaliGemma: A versatile 3B VLM for transfer

PaliGemma es un modelo de visión-lenguaje basado en el codificador de visión SigLIP-So400m y el modelo de lenguaje Gemma-2B. Está diseñado para ser un modelo base versátil y efectivo para la transferencia en tareas diversas.
The Background Note📝: PaliGemma promete ser un modelo base potente, pero su rendimiento en tareas especializadas necesita más pruebas para confirmar su versatilidad.
¡Espero que disfrutes de la lectura y encuentres estas investigaciones tan fascinantes como yo!
Gracias por leer The Background, 🤗 no olvides compartir este contenido con quien creas que le servirá. Hasta la próxima🫡.