


Solo se necesitaba atención
Solo se necesitaba atención
Breve historia sobre el origen del Transformador


Las redes neuronales recurrentes (RNN) fueron por mucho tiempo la elección principal para el modelado de secuencias y problemas de transducción. Sin embargo, a medida que los esfuerzos por mejorar estos modelos se intensificaban, también lo hacían las limitaciones inherentes a su estructura. La aparición de los Transformers en 2017 marcó un punto de inflexión, revolucionando el campo de la inteligencia artificial y superando muchas de las barreras que presentaban las RNN y aquí te cuento la razón.
Redes Neuronales Recurrentes
Las RNN procesan las secuencias de datos considerando la información de cada símbolo en relación con los anteriores y posteriores.
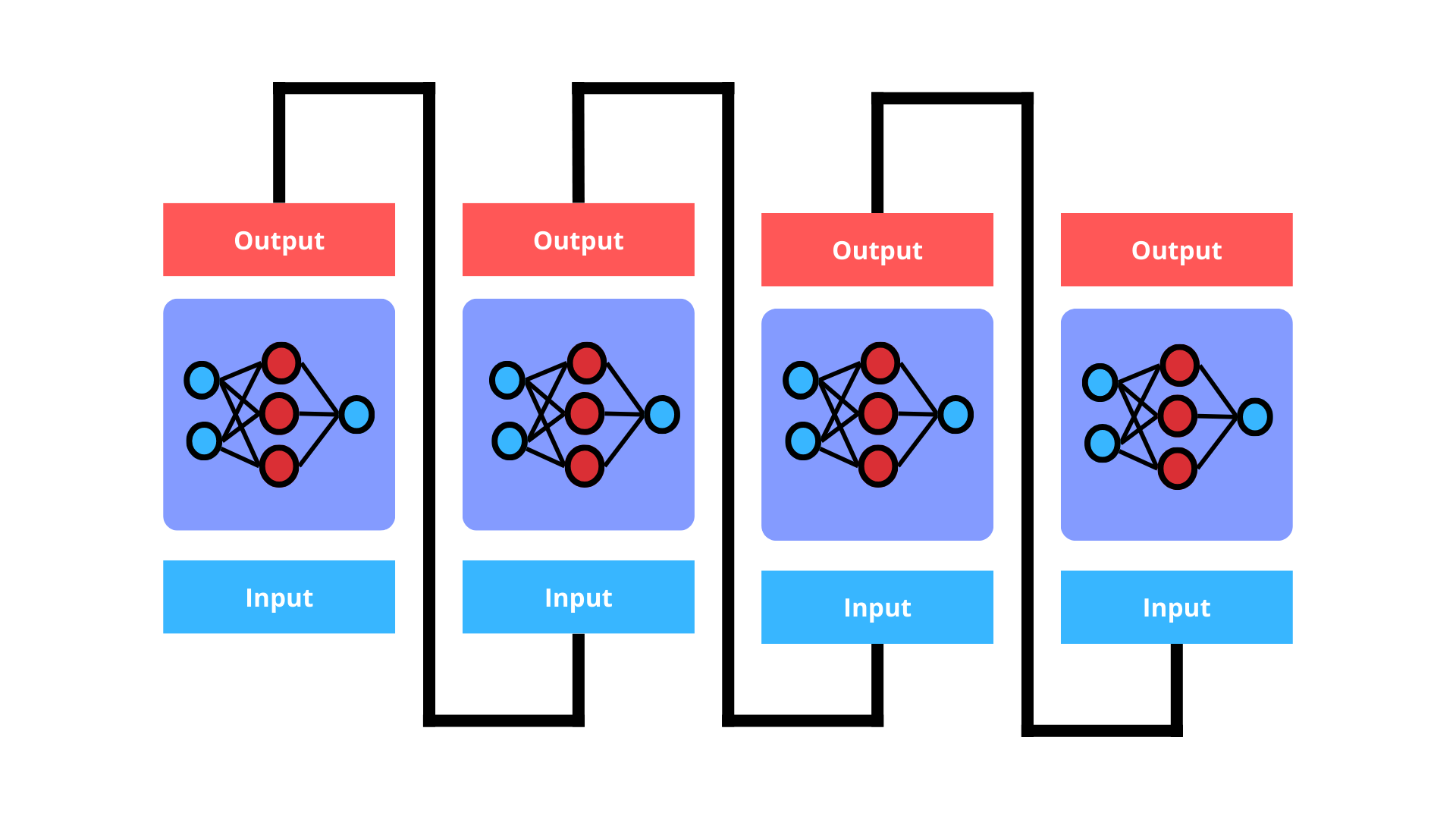
sta interdependencia implica que el cálculo debe hacerse de manera secuencial, lo que limita significativamente la capacidad de paralelización durante el entrenamiento. Este proceso secuencial es particularmente problemático para secuencias largas, ya que incrementa las demandas de memoria y tiempo de cómputo.
Mecanismos de Atención
Para superar las limitaciones de las RNN, se exploraron diversas alternativas, incluyendo nuevas arquitecturas y funciones de activación mejoradas. No obstante, estos enfoques no lograban solucionar completamente los problemas inherentes a las RNN.
Los mecanismos de atención, en cambio, presentaron una solución innovadora.
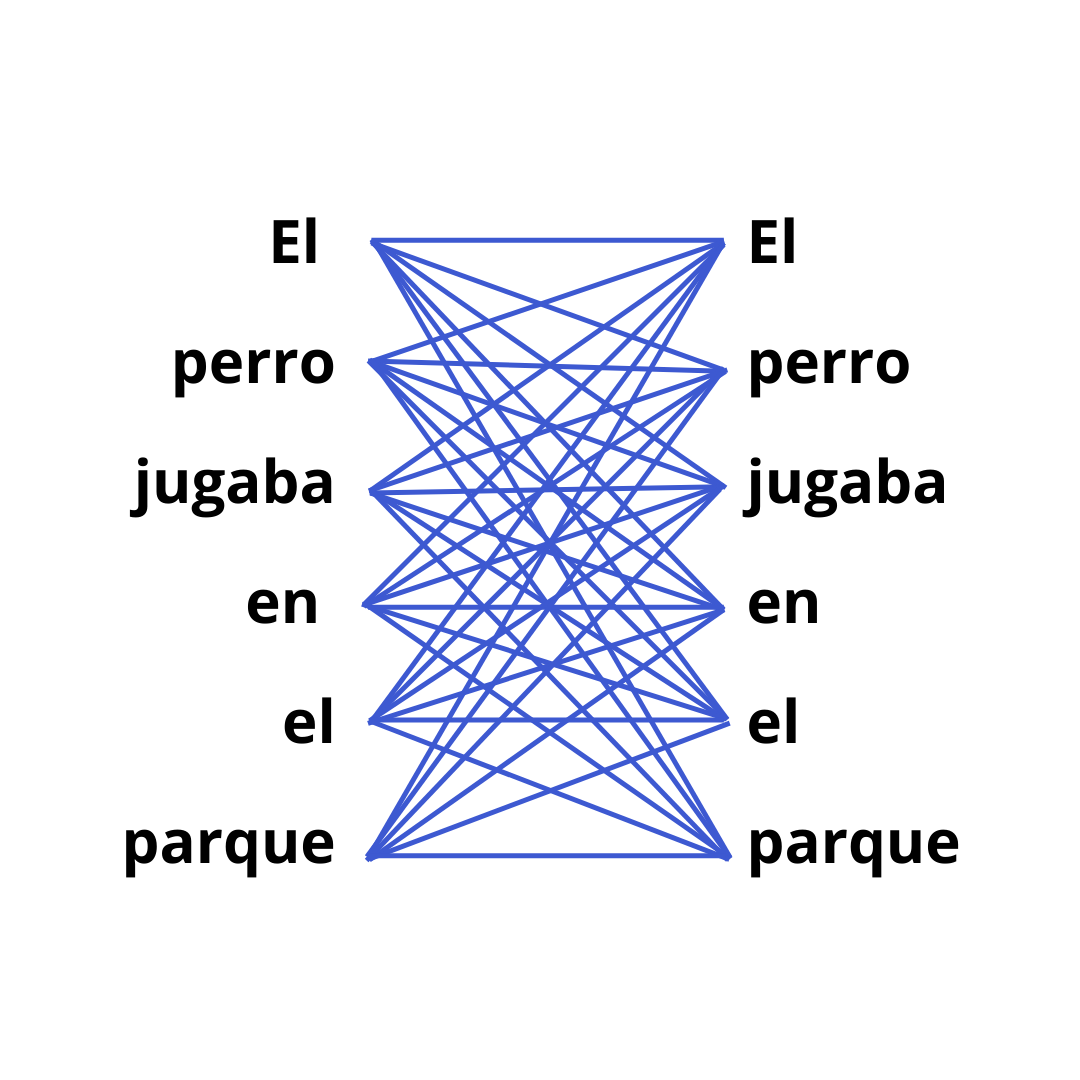
Estos mecanismos funcionan evaluando la importancia de cada vector de entrada con respecto a los demás, permitiendo al modelo enfocarse en las partes más relevantes de la secuencia. Esto no solo mejoró el manejo de secuencias largas sino que también facilitó la paralelización del entrenamiento.
El Transformador
Propuesto en el icónico artículo "Attention is All You Need" en 2017, el Transformador es una arquitectura basada exclusivamente en mecanismos de atención, eliminando la necesidad de recurrencia y convoluciones.
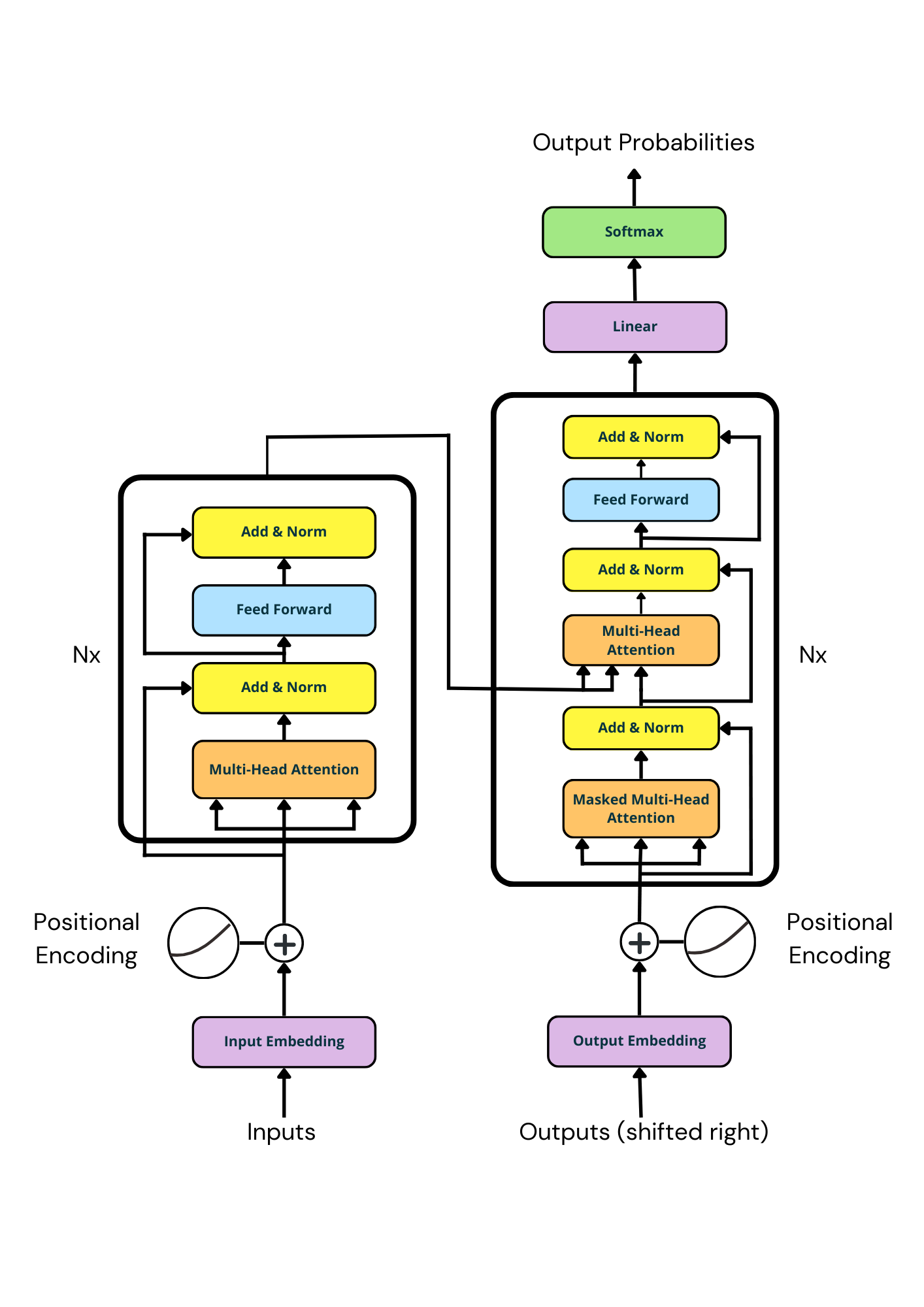
La principal ventaja de los Transformadores radica en su capacidad para procesar múltiples símbolos simultáneamente, lo que permite una paralelización efectiva durante el entrenamiento. Esto ha llevado a que los Transformadores se conviertan en el estándar para el modelado de secuencias y se adapten a otros campos, como la visión computacional con los Transformadores de Vision.
Algo interesante con respecto a esta arquitectura es que su estructura paralelizable ha permitido toda esta ola de nuevos modelos, esto debido a que es posible realizar entrenamientos mas grandes distribuyendo en trabajo en el hardware.
En los últimos años, esta arquitectura ha sido la base de grandes avances en inteligencia artificial. Modelos grandes de lenguaje como GPT-4 pueden generar artículos completos a partir de una breve frase, mientras que DALL-E o Midjourney crean imágenes a partir de breves descripciones gracias al uso de este modelo. Incluso en el ámbito de la conducción autónoma, el nuevo Autopilot de Tesla utiliza principios derivados de los Transformadores.
Se me hace un poco irónico que los modelos mas icónicos y conocidos por el publico sean los GPT de OpenAI (el dolor de cabeza actual de Google), siendo Google el creador del Transformador.
Conclusión
A solo siete años de su introducción, los Transformadores y sus variantes dominan en diversos campos de la inteligencia artificial, gracias a sus ventajas únicas en el manejo de secuencias y paralelización. Lo más notable es cómo una sola arquitectura base ha inspirado investigaciones y aplicaciones en múltiples dominios, demostrando su versatilidad y capacidad para impulsar la innovación en IA.
Gracias por leer The Background, en próximos artículos exploraremos mas a fondo conceptos como Modelos grandes de Lenguaje (LLM), Transformadores de Visión o Mecanismos de atención. Hasta la próxima.